Introducing DeCANT, a context-conditioned, attention-based multimodal architecture for creative pre-testing
The underlying mechanics of modern digital advertising systems have become increasingly opaque to advertisers. In testimony during an antitrust trial against Google, brought by the U.S. Department of Justice, Professor Kinshuk Jerath of Columbia Business School described Google’s advertising platform as a “black box,” noting that “Google controls the rules and influences the outcomes of its auctions and these auctions are a black box to advertisers.”
This opacity constrains the advertiser’s ability to systematically influence campaign outcomes. When platforms absorb ad retrieval and ranking into deep network architectures, much of the predictive calculus used to determine whether an ad is shown to any consumer group is abstracted. This leaves the advertiser with relatively few levers of control over the delivery of its ads: namely, the advertising creative used and the bid submitted to the auction.
This highlights an important operational reality: the underlying mechanics of ad candidate generation, ranking, and auction allocation are latent, only partially observed, dynamic, and not directly identifiable from advertiser-side data.
This limitation has become more acute in the past few years as platforms increasingly abstract digital advertising campaign optimization into wholly automated, “AI-enriched” platform tools such as Meta’s Advantage+ and Google’s Performance Max. From the advertiser’s perspective, these platforms operate as opaque end-to-end systems: a small number of inputs are ingested, and outcomes are observed. In that sense, any given end-to-end automated platform can be viewed as a teacher model — a unified latent process — that accepts structured input and produces context-conditioned output (conversion events).
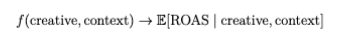
As I note in The creative flood and the ad testing trap, many advertisers have embraced the generative creative production tools provided to them by large platforms and independent tool providers alike, resulting in ever-larger volumes of ad creative being utilized in campaigns. In a blog post about its Andromeda retrieval system, Meta acknowledges an “exponential growth in volume of eligible ads available to the retrieval stage”; in its Q4 2025 earnings call, Alphabet noted that 70MM creative assets were generated through text customization in its automation tools in that quarter alone. Larger volumes of ad creative, produced through generative tools, can increase the surface area of exploration for an advertiser, as I argue in Producing and deploying advertising creative at scale and Abandoning intuition: using Generative AI for advertising creative. But merely increasing the volume of output without materially expanding the themes, concepts, color schemes, aesthetic styles, and overall messaging structure of that creative is unlikely to deliver performance gains. And it may, in fact, cause an advertiser’s testing budget to inflate, as each piece of creative needs to be supported with ad spend to assess potential.
It is for this reason that I present DeCANT: a Deep Creative Attention-based Network for pre-Testing. This article is an intentionally simplified, reduced-form synthesis of my recently defended master’s thesis; it describes the empirical environment in which DeCANT was tested, its results, its interpretation, and a framework for implementation.
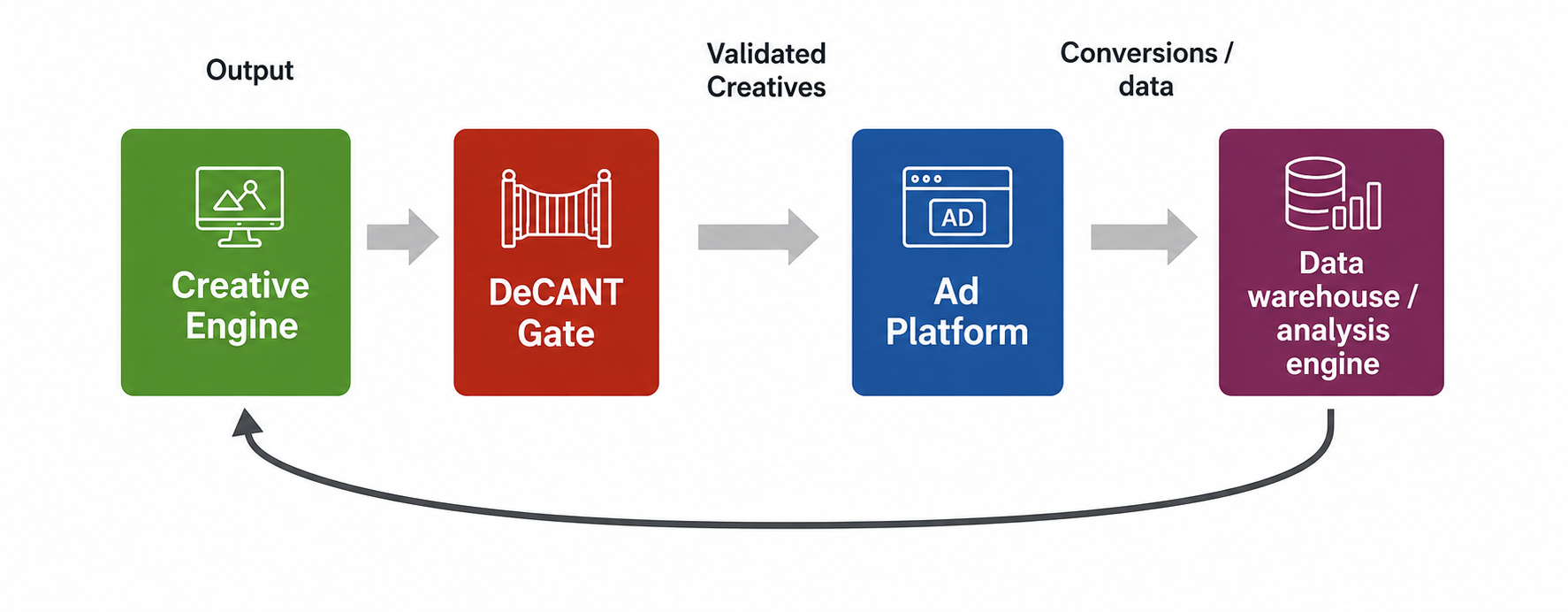
Operationally, DeCANT functions as a pre-testing gate within a creative production workflow: given the context into which an ad is exposed (country, language, channel, and potentially other factors) and the creative that comprises an ad (for DeCANT, static image or video), DeCANT predicts the resulting ROAS in a way that can be used to determine whether or not the creative should be tested.
Conceptually, the DeCANT approach is rooted in two central premises:
First, the cost of creative production has declined substantially with the general availability of generative tools, enabling advertisers to explore a large space of creative variations without relying exclusively on prior intuition or heuristic-driven design.
Second, the context in which an ad is served conveys critical information for performance, implying that higher-order interactions between creative attributes and contextual features must be explicitly modeled.
That second point is important: it presupposes that context is an integral component of ad performance, and that higher-order interactions between contextual features and media features (the creative itself) influence ROAS.
Further, there are limitations to this approach:
- It assumes that the advertiser has access to a consistent, defensible ROAS measurement framework, even if that framework is imperfect.
- It assumes that advertiser bids and bid strategies are homogeneous across ad creatives.
- It doesn’t account for dramatic, exogenous market-based (auction) shifts that might undermine ROAS predictability.
These limitations are real and should be accounted for in a marketing process. But as advertising platforms increasingly abstract away the mechanics that determine advertising performance, the “black box” nature of ROAS can be viewed as a latent process that can be learned and modeled. In this framing, advertiser-side modeling becomes a form of behavioral distillation: the advertiser attempts to approximate the platform’s latent decision surface using observed outcomes.
In other words: the advertiser “abandons intuition” and, rather than infer performance through the various attributes of advertising that have historically correlated with success, they utilize a pre-testing filter that attempts to apply the learned representations from the teacher model into a quantified target.
The broader implication is that advertisers do not need full visibility into platform retrieval and ranking systems to build useful decision-support scaffolding around them. They need disciplined data structure, multimodal creative representation, and a workflow that produces testing decisions. The DeCANT architecture is one application of this framework.
Empirical setting
The empirical analysis in this work is conducted using proprietary advertising performance data provided by Fabulous SAS, a publisher of a portfolio of health and wellness mobile applications. The dataset contains nearly 100,000 ad-level observations spanning more than 10,000 unique creatives, exclusively deployed on Meta’s advertising surfaces. Each observation represents a specific instance of a creative deployed within a particular contextual configuration (e.g., time, geography, and campaign attributes), paired with an observed performance outcome.
A key feature of the dataset is its multimodal nature. Each creative is associated with:
- A visual asset (image), in some cases extracted as a snapshot from a video by the platform;
- Any textual content present in the image, obtained via optical character recognition (OCR) applied to the creative;
- A free-form semantic summary of the creative message;
- Structured contextual metadata describing the conditions under which the ad was served;
Because certain creatives are reused across multiple contextual settings, the dataset naturally reflects a many-to-one mapping between observations and creative assets. This structure is central to the modeling approach, as it enables the separation of creative-specific and context-specific effects.
The design matrix is constructed through a preprocessing pipeline:
- Each unique creative is hashed to avoid duplication;
- Various numeric and qualitative features are extracted from each unique creative from an LLM (Gemini 3 Flash Preview);
- Image embeddings from the ad creatives are created with a visual transformer embedding model;
- Text embeddings (OCR text and image summary) are created with a sentence transformer embedding model.
The design matrix is then saved to a single file, and the train-validation-test splits are made based on hashed creative identifiers to ensure that no creative appears in multiple data sets.
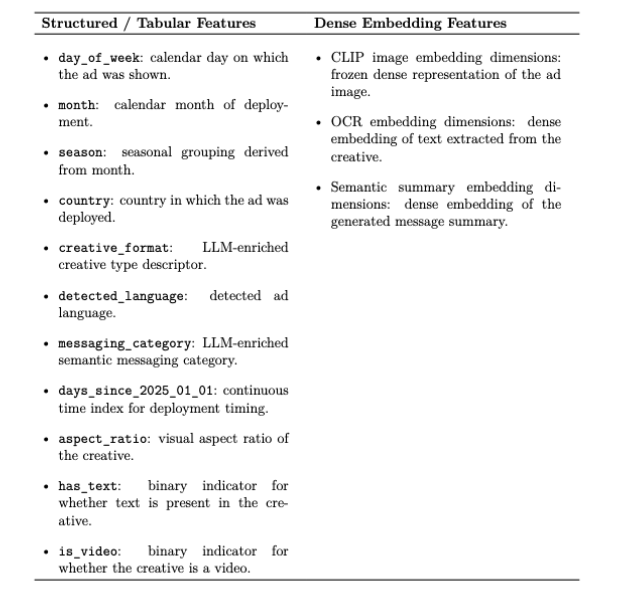
The target variable is ROAS, specifically: 30-day ROAS as measured from the date of the first ad instance (creative and context combination). Because ROAS is heavy-tailed and zero-inflated, the target variable is transformed with:
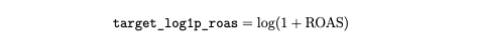
Model architecture and testing approach
Several tabular models were used to establish baseline performance. Of these, XGBoost performed best. Thus, the core hypothesis of the exercise — that context conditioning is a critical factor in predicting ROAS in a multimodal advertising environment — was evaluated by interrogating whether an attention-based multimodal architecture better captures context-creative interactions than a tree-based model.
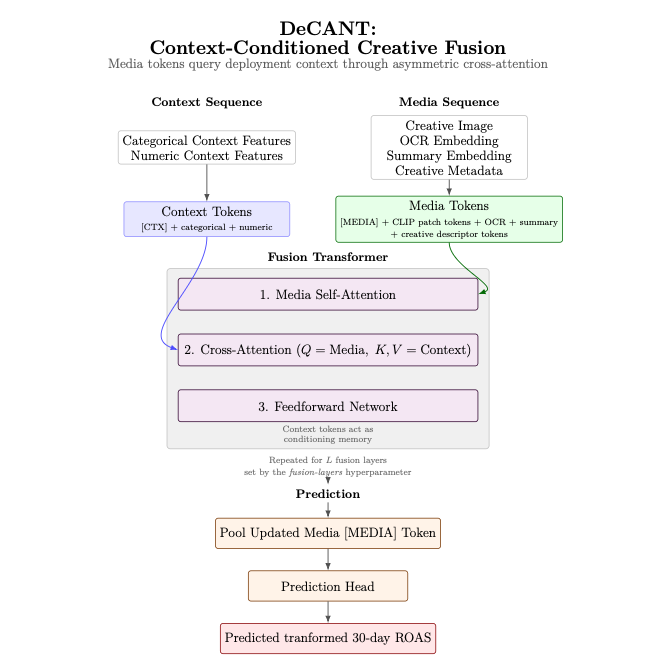
To do this, the DeCANT model decomposes the feature space into two token streams: context tokens and media tokens. The context token sequence consists of one token per structured feature. Each categorical variable is mapped to a dense embedding through a learned lookup table, while the single numeric variable (days since January 1st, 2025) is projected into the same latent space via a learned linear transformation. In addition to these feature-specific tokens, a learned aggregation token, denoted [CTX], is prepended to the sequence. The resulting context representation can be written as:
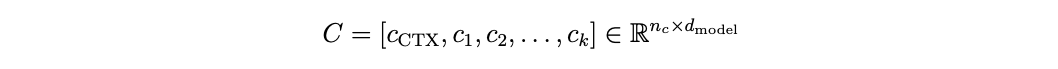
The media token sequence is constructed from multimodal representations of the creative. The image is processed using a vision transformer encoder, producing a sequence of patch-level embeddings. These image tokens are augmented with additional creative-side tokens representing OCR-extracted text, a semantic summary of the creative message, and structured creative descriptors. Specifically, single tokens are appended for OCR text and summary embeddings, while LLM-generated categorical descriptors such as creative format, detected language, and messaging category are encoded via trainable embedding lookup tables. Numeric descriptors such as aspect ratio and binary creative indicators are projected into the shared latent space as learned tokens. In addition, a learned aggregation token, denoted [MEDIA], is prepended to the sequence. This yields:
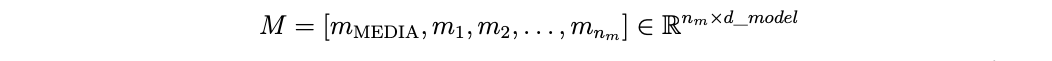
These token streams are then processed by an asymmetric fusion transformer, per the diagram above. The pooled media token is first updated through self-attention, and it queries the context token sequence via a subsequent cross-attention layer. The standard scaled dot-product attention mechanism is used:
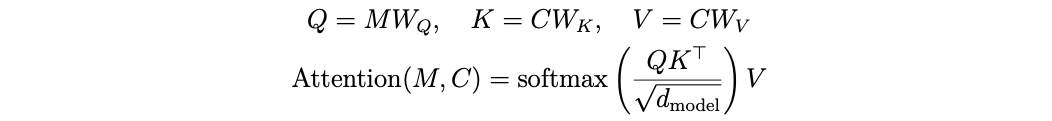
Conceptually, DeCANT attempts to model advertising performance as an interaction between two distinct information streams: the deployment context of the ad and the semantic structure of the multimodal creative itself. Rather than flattening these features into a single vector, the architecture preserves them as separate token sequences and models their interactions through cross-attention. Cross-attention allows the model to condition the semantic interpretation of a creative on the environment in which it is deployed. This is important because in practice, advertisers rarely care whether a creative performs well in isolation; they care whether it performs well within a specific deployment context.
Multiple ablations were tested across several architectural variants, including partial unfreezing of the image encoder, which yielded the strongest results in this setting.
On the held-out test dataset, DeCANT outperformed XGBoost on both MAE and MSE
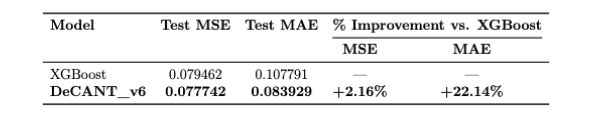
This result is consistent with the distribution of the target variable, target_log1p_roas. MSE places disproportionate weight on relatively rare large errors, making it sensitive to tail behavior. By contrast, MAE weights all deviations linearly and so provides a more representative measure of performance across typical observations. But both metrics are informative: MSE is used for model selection, while MAE provides a complementary view of performance across typical advertiser outcomes.
More broadly, DeCANT’s outperformance on the held-out test set supports the central claim of the exercise: that modeling interactions between creative content and deployment context through cross-attentive fusion yields measurable gains in advertiser-side predictive performance.
Interpretation
To evaluate how DeCANT and XGBoost respond to changes in deployment context, an interpretation pipeline was developed as a behavioral stress test. The objective is to quantify how each model’s prediction changes when contextual variables are altered while the creative itself is held fixed, given the absence of counterfactuals. Differences in these responses provide interpretable measures of how each model weights and combines contextual inputs.
For each sampled row, three perturbation regimes are constructed: weekday, month/season, and country. Within each regime, perturbations are applied at increasing orders (single, double, triple), while the creative (media) features are held fixed. Model behavior is then measured as the absolute change in prediction relative to the baseline row.
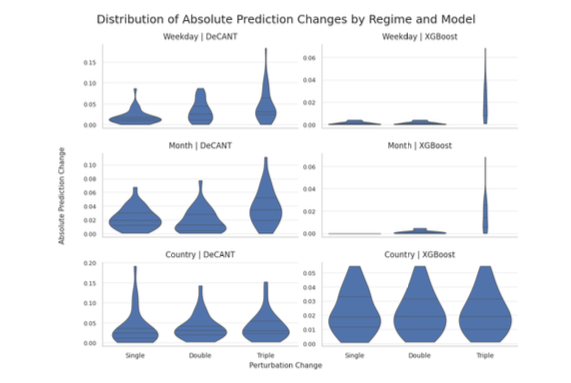
Two differences are evident from the perturbation exercise. First, XGBoost exhibits highly concentrated sensitivity to a single contextual dimension: Country. Its predictions respond meaningfully to country perturbations, but show minimal movement under weekday and month changes. For example, weekday perturbations produce negligible changes relative to DeCANT (roughly an order of magnitude smaller), and month perturbations produce effectively no response at lower perturbation orders. Moreover, this response does not increase meaningfully as perturbations compound, indicating limited sensitivity to higher-order combinations of context features. This pattern suggests that XGBoost primarily captures dominant marginal effects, effectively reducing context into a small number of high-signal variables.
By contrast, DeCANT showcases compositional sensitivity to singular context perturbations as well as their combinations. Its predictions shift across all three regimes, and these shifts generally increase as perturbations compound from single to double to triple changes. This behavior indicates that DeCANT not only incorporates multiple contextual dimensions but also combines them, producing larger prediction adjustments when context changes along multiple axes simultaneously. This pattern is especially evident in the violin plots above, where DeCANT shows both larger and more dispersed prediction changes across regimes.
These results provide behavioral evidence for the core hypothesis of this exercise. DeCANT, by design, conditions the creative representation on contextual inputs through cross-attention, enabling it to capture interactions between context features. The interpretation results show that DeCANT responds to multiple contextual dimensions and their combinations, whereas XGBoost primarily captures independent marginal effects. Taken together, this suggests that DeCANT’s performance gains arise from its ability to incorporate context-conditioned interactions into its predictions.
Implementation
The introduction of generative tools for advertising creative production has enabled advertisers to rapidly test messaging, brand identity, aesthetic, and promotional concepts at minimal production cost. This is helpful for optimizing advertising strategy and exploring the conceptual landscape of creative, which is vast and not well served by human intuition. It also reflects the power of modern “black box” advertising platforms, which use sophisticated approaches to candidate retrieval, ranking, and auction allocation.
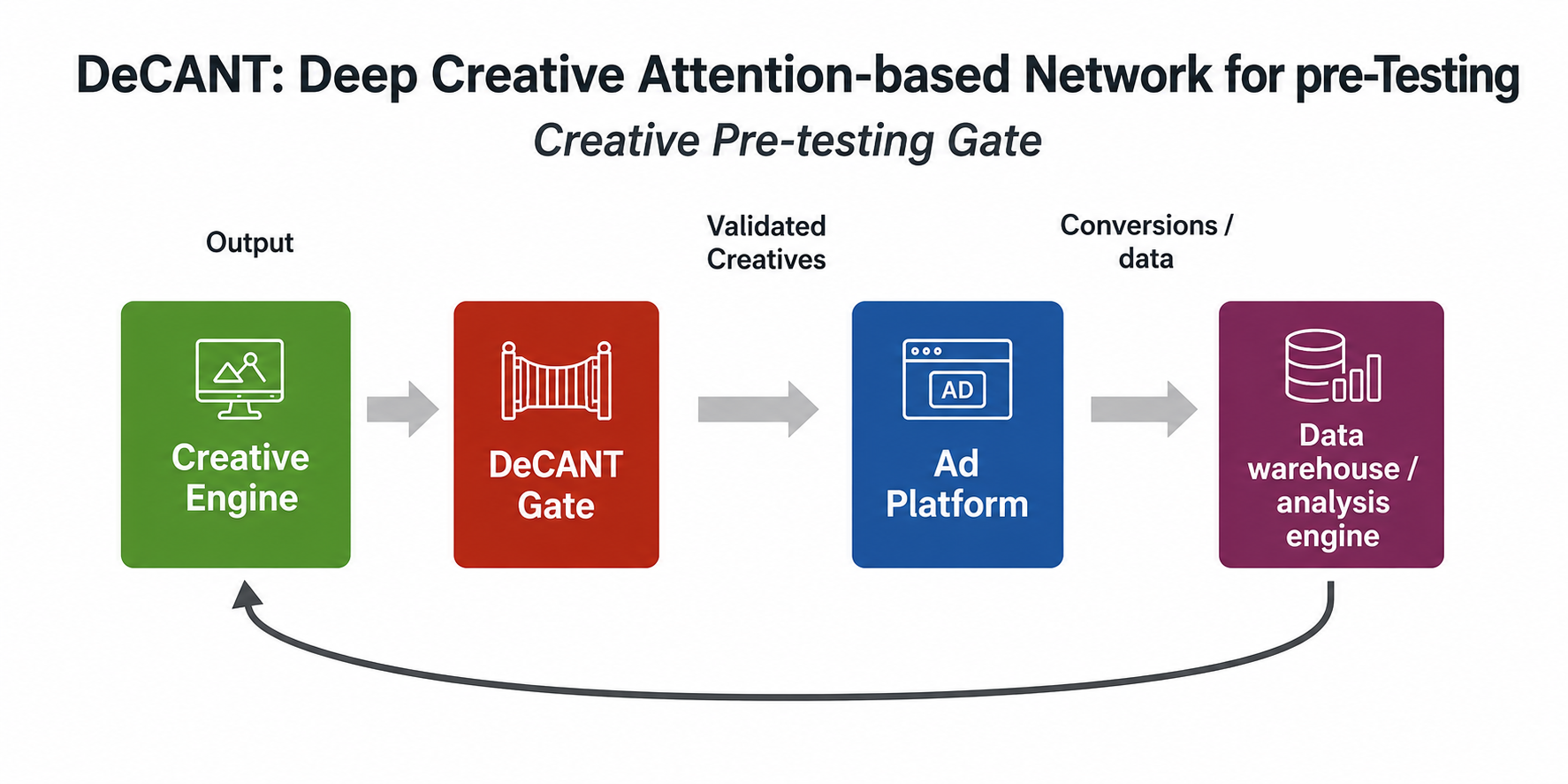
A model like DeCANT can be used in a pre-testing workflow to determine which creatives are likely to deliver acceptable ROAS, thereby minimizing the testing budget. This process serves as an automated filter: creatives are produced through a generative pipeline, and the student model that learns the process for the given advertising channel is invoked on the proposed creative and context. The model generates an expected ROAS, which is compared against the advertiser’s testing threshold to determine whether the creative is uploaded to the platform.
In this framework, the model serves as a pre-testing filter within the creative production and deployment process. Historically, advertisers evaluated creative through heuristic frameworks (“best practices,” visual conventions, messaging rules, etc.). DeCANT instead attempts to learn the latent structure of platform-evaluated performance directly from outcomes.
Because the model is trained as a latent student of a given platform’s performance evaluation (“teacher model”), it is directly dependent on platform performance in defining its objective and thus is acutely sensitive to changes in the teacher model. For this reason, a model of this type must be re-trained on a regular schedule; perhaps as frequently as weekly or even daily. However, this is not meaningfully cost-prohibitive: training DeCANT across all versions and ablations amounted to roughly $1,000 in total cloud computing spend. This represents a trivial cost for many scaled digital advertisers.
Comments: